
Contents
Legacy note now is here
I moved this note from the 2010 original on my Blogspot notes (here) into my WordPress domain (below) on 26Oct2020. The reason was that I discovered that TIOBE Software BV now relates to Cyclomatic Complexity, and in fact seems to calculate it on the source code that they analyse. They may have done this for years, but I think it was only now that they brought it into the attention on their first page. They use the TICSpp tool, which is part of TIOBE’s TICS framework [10].
The wording is the same as the 2010 note, but I did modernise the code views and some of the other styling. I may have changed opinion, I may not..
2020
A small thread with TIOBE Software in Nov2020. Starting with my initial mail. I have been allowed to quote it as signed:
| I am a retired programmer who do some coding and blogging. I discovered the TIOBE Quality Indicator on your front page and then I indulged in the Cyclomatic Complexity there. I then wiped the dust off an old web post from 2010, that I moved into my present WordPress. It discusses a case where STPTH / STCYC is a not much useful metrics. But there is another matter that is the reason for writing this mail: Since I have used and made so many runtimes for language + runtime scheduler = concurrent (=not parallel), and having used occam in the nineties (for transputer) and now do a lot of xC (for XMOS xCore architectures), both languages support both concurrent and parallel coding ,I wondered whether you have any Quality Indicator for how well a certain language would do concurrent or parallel programming? The xC language for the xCORE architecture by XMOS has a lot of parallel usage verification that will issue error messages (here). It also has deterministic scheduling, and timing requirements may be set up, and the compiler takes it. It also has three types of tasks: standard, combinable and distributable – worth a study by its own means (here). Of course «nobody» in your test domain would do any coding in xC. But still, how do you think about concurrent (and/or parallel) languages? |
|
Thanks a lot for your mail! Concerning cyclomatic complexity. I am quite happy with this metric. It is easy to calculate and gives a fairly good indication of complexity and testability. There is always discussion about the way «switch-case» statements are counted. This is something we might change in the future. Static path count is indeed horrible with results that run into millions of paths for a function. This is only understandable if you take the logarithm of the path count and then you are more or less back to cyclomatic complexity:) |
Stay tuned, this thread is supposed to be extended.
Original 2010 note
Background
The software metric STPTH («static path count») some times yields an unacceptably worrying figure. The higher the worse, like 6000, which is really bad – signifying a high code complexity. However, is it the code or the formula that’s unacceptable? Let’s try to find out.
The fairy tale of «Hansel and Gretel»
In this fairy tale [9], when Hansel and Gretel are left alone deep in the forest, Hansel has left a trail of white pebbles (stones) which their parents did not notice. To find home again, Hansel and Gretel just followed this trail. But the next day, they cannot find home because Hansel made the trail of bread crumbs. The birds ate the bread, and the forest became dangerous. They were lost.
The first day the forest was not dangerous, the second day it was.
Even in a fairy tale the context or trail is important. A child can understand it. So, why should a high STPTH number always be bad? You tell me!
STPTH – what is it?
STPTH seems to be defined in the now superseded ISO/IEC 9126 Quality Attribute Model [1]. The [1] Wikipedia article does not mention the sub-characteristic attribute tree: maintainability – complexity – static path count, which [2] does. The figure is a screen clip from [2]. (Update Nov2020: I could not find it there any more. The original bitmap is here. The PDF below I have drawn anew in 2020. PDF here):
iso_9126_quality_attribute_model_new_2020_alike_wikipedia_2010 I have not been able to find the formula, but the number of branches is in it. However, in order to clarify, let’s look at the difference between STPTH («static path count») and STCYC («cyclomatic complexity»). Quoting from a mail, where I had queried about these matters: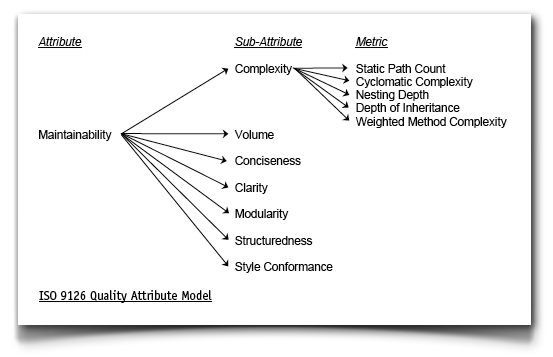{kind=link}
..It is very easy to generate code with a large value of STPTH because the algorithm for computing STPTH is simplistic. For example, the addition of a switch construct with 5 branches will add 5 to the value of STCYC but will multiply the value of STPTH by 5.
In other words: if then else and switch case code is expensive STPTH-wise. But watch out, there is at least a case where STPTH is not very meaningful: high number is ok. It’s worse: the normal figure is high!
Recently I queried the English company Programming Research and they replied:
This is similar to Nejmeh’s (1988) NPATH statistic and gives an upper bound on the number of possible paths in the control flow of the function.
I found a reference and explanation in [3]. Npath is the name of a tool computing the NPATH measure and other measures. Quoting from [3]:
The NPATH metric computes the number of possible execution paths through a function. It takes into account the nesting of conditional statements and multi-part boolean expressions (e.g.,
A && B,C || D, etc.). Nejmeh says that his group had an informal NPATH limit of 200 on individual routines; functions that exceeded this value were candidates for further decomposition – or at least a closer look.
Also, [3] references the real source of it all, namely and article by Brian Nejmeh in 1988 [4].
An example
Programming Research gave me this example, knowing that I was writing this blog, so I assume it’s ok to quote here (italics):
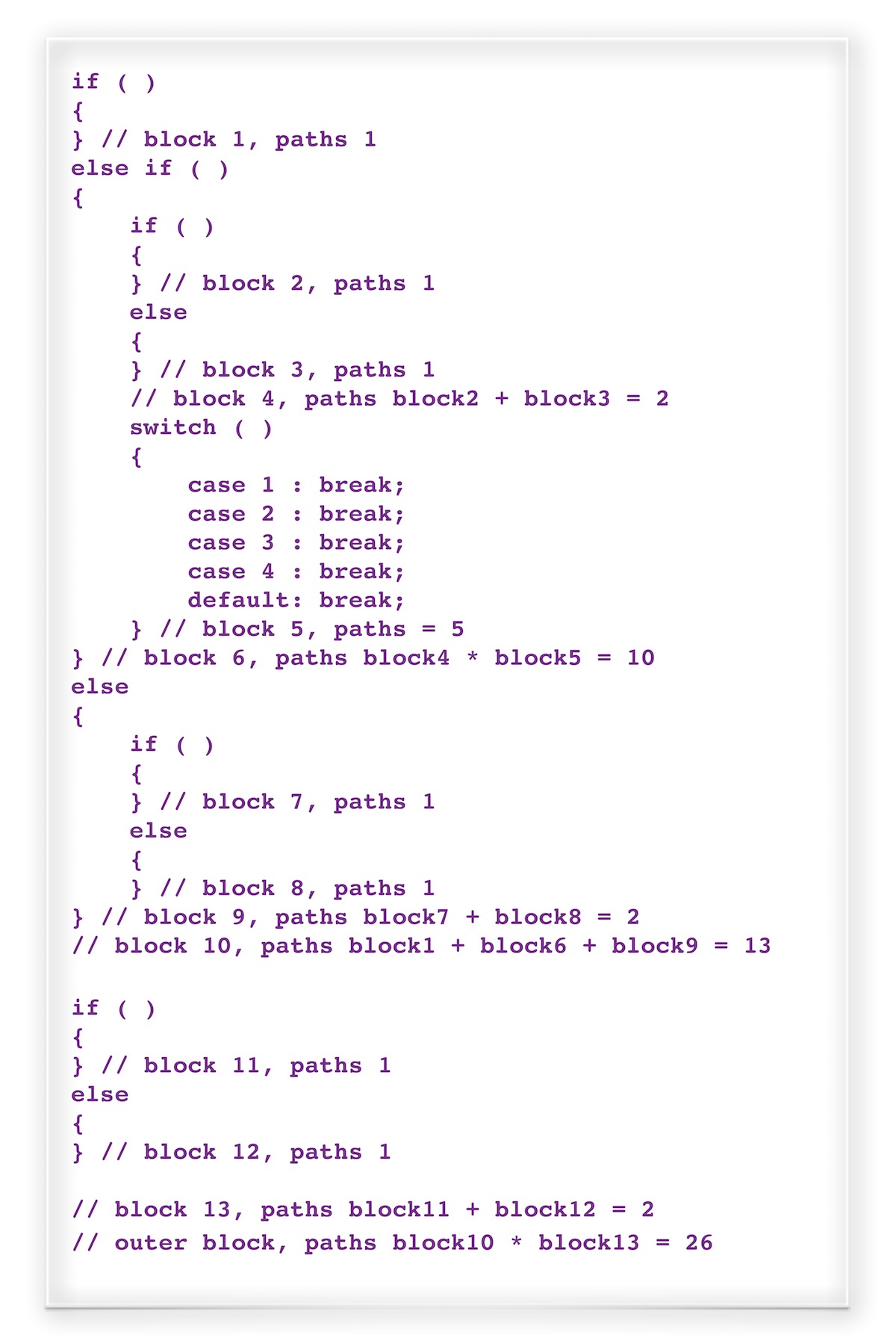
The following code example has a static path count of 26 (2010 bitmap):
{kind=link}
if ( )
{
} // block 1, paths 1
else if ( )
{
if ( )
{
} // block 2, paths 1
else
{
} // block 3, paths 1
// block 4, paths block2 + block3 = 2
switch ( )
{
case 1 : break;
case 2 : break;
case 3 : break;
case 4 : break;
default: break;
} // block 5, paths = 5
} // block 6, paths block4 * block5 = 10
else
{
if ( )
{
} // block 7, paths 1
else
{
} // block 8, paths 1
} // block 9, paths block7 + block8 = 2
// block 10, paths block1 + block6 + block9 = 13
if ( )
{
} // block 11, paths 1
else
{
} // block 12, paths 1
// block 13, paths block11 + block12 = 2
// outer block, paths block10 * block13 = 26
Each condition is treated as disjoint. In other words no conclusions are drawn about a condition which is being tested more than once. The true path count through a function may therefore be lower than the estimated static path count but will never be less than the Cyclomatic Complexity (STCYC).
The true path count through a function usually obeys the inequality:
Cyclomatic Complexity <= true path count <= Static Path Count
Our code example
The code is discussed in [5]. Here is the start of it ( (2010 bitmap):
{kind=link}
Void P_Prefix (void) // extended “Prefix”
{
Prefix_CP_a CP = (Prefix_CP_a)g_CP; // get process Context from Scheduler
PROCTOR_PREFIX() // jump table (see Section 2)
... some initialisation
SET_EGGTIMER (CHAN_EGGTIMER, CP->LED_Timeout_Tick);
SET_REPTIMER (CHAN_REPTIMER, ADC_TIME_TICKS);
CHAN_OUT (CHAN_DATA_0, &CP->Data_0, sizeof(CP->Data_0)); // first output
while (TRUE)
{
ALT(); // this is the needed ”PRI_ALT”
ALT_EGGREPTIMER_IN (CHAN_EGGTIMER);
ALT_EGGREPTIMER_IN (CHAN_REPTIMER);
gALT_SIGNAL_CHAN_IN (CHAN_SIGNAL_AD_READY);
ALT_CHAN_IN (CHAN_DATA_2, &CP->Data_2, sizeof (CP->Data_2));
ALT_ALTTIMER_IN (CHAN_ALTTIMER, TIME_TICKS_100_MSECS);
gALT_END();
switch (g_ThisChannelId)
{
... process the guard that has been taken, e.g. CHAN_DATA_2
CHAN_OUT (CHAN_DATA_0, &CP->Data_0, sizeof (CP->Data_0));
};
}
}
There are 3 visible synchronization points in this code: lines 08, 17 and 21. The channel based scheduler is one return away from the code you see here. The PROCTOR_PREFIX in line 04 is an invisible branch table to invisible labels hidden inside the macros of the synchronization points.
When a channel (or one of a set of channels in the ALT) is first on the channel, there is a return to the scheduler, to implement the blocking semantics of a synchronous channel based scheduler. This scheduling is called cooperative scheduling, and all the code you see is plain ANSI-C with zero tricks – other than the fact that the branch proctor table is made with a script which searches for the labels. «The channels is the scheduling» with these systems, except for the asynchronous no-data signal channel we have implemented. The Wikipedia article [6] is not very relevant though, since it does not explain cooperative multitasking in use for a CSP (Communicating Sequential Processes) based system (March ’10). Ada could have used that scheme, occam[7] does, as does our system. These systems could be, and ours is, non-preemptive. Therefore no assembler or tricks, since I don’t think it is possible to write a preemptive scheduler in ANSI C without relegating to assembly. I cannot find a suitable Wikipedia article for this.
The problem with this code is that it is much more complex than it looks.
Some of the channel macros are in-line code with conditionals. (I don’t like macros, but with ANSI-C I tend to love them.) And, when we receive something on a channel, it’s not handled inside the ALT structure (as would occam or Ada), but in the nice switch (g_ThisChannelId ) case block below. Also, the fold in line 20, which would contain 5 case branches. Inside these cases one would usually check the received protocol in a level or two, and then innermost we could send off a CHAN_OUT.
This inner CHAN_OUTcannot be done from a function! There is no other way, with the non-preemptive cooperative scheduler we use.
Aside: it’s not as it was with the SPoC (Southampton Portable occam Compiler, [8]) which generated ANSI-C from occam. Occam allows communication on channels from any PROC (except from its side-effect free functions). So SPoC had to allow it. It used the same return to the scheduler (that’s where we learned this). The trick was to «flatten out» any PROC by not calling it, but starting it as a special type of PROCess, only to push the return down (any number of levels) to one above the scheduler. Alas, this is too complex for us to do by hand-written ANSI-C!
Still I would argue that the code above is as simple as it could be. In a code example at work, the STPTH value started at 13000, but I was able to reduce it to 6000. Then my willingness to fine tune any more came to a halt.
The fact that I took the energy to reduce by 50% showed that STPTH had some value!
A suggestion
Perhaps the tool that calculates the STPTH for us could see these inner synchronization points that cannot be put into called functions and «excuse» them? We could decorate that inner point with an exception rule that could enter into the formula. That way we could get STPTH down to some value that we won’t have to explain.
In the reports we get an overview of all exceptions, so it won’t be forgotten.
I would certainly like comments on this. How should the exception modify the STPTH formula?
One solution
After some lamenting to the tool vendors and pondering, we decided to make some conditional compilation #ifdef __STPTH_TOOL__ and remove the PROCTOR_PREFIX‘s automatically generated jump (goto, scheduling) table and also the synchronization points (channel input and output, gALT_END etc.). Nowhere to jump from and nowhere to jump to! Or, hide scheduling from the tool.
Here is the «Code Review Document» with a process containing the jumps to synchronization points: And here it is after we made the scheduling and synchronization linking invisible to the tool:
And here it is after we made the scheduling and synchronization linking invisible to the tool:
The STPTH went from 33 mill to 220 thousand! The file has 2000 lines of code. This is a process file that relates to process context structure that we never parameterize in an extern call. We take elements of it and parameterise, of course. The file is folded, so I only relate to «single screens» anyhow. This is rather good, even if the purists would say the STPTH number is way too high! But look at the structure now. In my opinion it is rather organised.
We only placed the #ifdefs in the scheduler’s .h file, where all the macros we use are defined. Not a single change in the process files. But we had to rewrite to PROCTOR_PREFIX table generator program to also include this #ifdef in the generated file.
References
- ISO 9126 international standard for the evaluation of software quality http://en.wikipedia.org/wiki/ISO_9126.
- Improving Software Quality through Static Analysis, in http://findbugs.cs.umd.edu/talks/JavaOne2007-TS2007.pdf (Pugh) and http://www.cs.umd.edu/~jfoster/papers/paste07.pdf (Foster, Hicks, Pugh)
- npath – C Source Complexity Measures, see http://www.geonius.com/software/tools/npath.html
- Brian Nejmeh: NPATH: A Measure of Execution Path Complexity and its Applications, in Communications of the ACM, Februrary 1988.
- New ALT for Application Timers and Synchronisation Point Scheduling. Two excerpts from a small channel based scheduler. Øyvind Teig and Per Johan Vannebo, Autronica Fire and Security (AFS) (A UTC Fire and Security company). In Communicating Process Architectures 2009 (WoTUG-32)
Peter Welch, Herman W. Roebbers, Jan F. Broenink, Frederick R.M. Barnes, Carl G. Ritson, Adam T. Sampson, Gardiner S. Stiles and Brian Vinter (Eds.) IOS Press, 2009 (135-144) ISBN 978-1-60750-065-0 © 2009 The authors and IOS Press. All rights reserved. See http://www.teigfam.net/oyvind/pub/pub_details.html#NewALT - Cooperative multitasking – http://en.wikipedia.org/wiki/Cooperative_Scheduling#Cooperative_multitasking.2Ftime-sharing
- Occam – http://en.wikipedia.org/wiki/Occam_(programming_language)
- Southampton’s Portable Occam Compiler (SPOC) (1994) by Mark Debbage, Mark Hill, Sean Wyke, Denis Nicole. Just search for this on the net. I also have several hands on papers with it, see http://www.teigfam.net/oyvind/pub/pub.html
- The fairy tale «Hansel and Gretel» – http://en.wikipedia.org/wiki/Hansel_and_Gretel
 TICS Fact Sheet by Tiobe Software BV, see https://www.tiobe.com/tics/fact-sheet/. Read how they do their searches: https://www.tiobe.com/tiobe-index/programming-languages-definition/. That is why I have added «ex cee programming» (almost that) at the pages of my blog where I show xC code, or the underlying structure in code in ex cee. The TIOBE Index is at https://www.tiobe.com/tiobe-index/
TICS Fact Sheet by Tiobe Software BV, see https://www.tiobe.com/tics/fact-sheet/. Read how they do their searches: https://www.tiobe.com/tiobe-index/programming-languages-definition/. That is why I have added «ex cee programming» (almost that) at the pages of my blog where I show xC code, or the underlying structure in code in ex cee. The TIOBE Index is at https://www.tiobe.com/tiobe-index/