I'll try to explain large files in this note.
We programmers often anthropomorphize about the semantics of programs: they run and stop and behave. Of course we do, since there is nothing like a dead line of code for us. Even if our programs some times are dead.
We need to understand what we do, and what we have done, years later. Worse (or better, it all depends) - we have to understand the programs that the guy who left wrote.
Some years ago I listened to a lecturer at a computer science conference. His speciality was version control, reuse and source tracking. How programmers in the company he worked for used program sources as basis in new products. Fixed them and fed them back in the system again. After analyzing the statistics, his #1 conclusion was that a program that was not in some state of development was dead. There was nothing like error free code for long, because, since it was often on the road again, new errors crept in.A program needs always to be understood. In our heads. Nice diagrams on paper or on screens don't understand. We do.
The diagrams and tools and methodologies are there only for us, as aids to help us separate - or merge - our concerns.
Even automatically generated code these days, is often laid out and structured in a way which is quite readable to humans. I have seen such automatic code both as one large file and broken into several.
I assume that design by functional decomposition has been done. Into mall, medium and rather large functions and even more complex processes (tasks, threads).
Functions are easier to put into smaller files, processes are worse. To export the process' context data struct and have external functions manipulate it, in my opinion, lessens the high cohesion an internal functional decomposition gives. It's more risky with an open abdomen.
However, larger internal state machines should or could be pulled out, with their structs imported to the process. Then the pointers to these structs are included into process context, and this pointer's memory is malloc'ed by a state machine init function. So, how large the files then become, is dependent on the design.
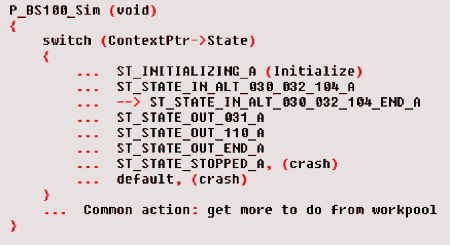
Now, is it a design goal to end up with several groups of smaller files, and should we avoid larger files by all means? Of course not - as long as a file is not bloating without thought. To have large files, if by design, is ok. Provided you and the other guy have a means to help understanding them.
I could say the same about "filelets" a word I saw in a discussion group (*1). An object with 5-10 lines of code, called by one user, one time - and hundreds of them in a project. Is this good decomposition? Classes are very small, objects small. Is there a "critical mass" average number of lines in the small files, for good understanding of the system? Of course there is. Massive interconnection may not be the best, if there are alternatives.
In the early eighties somebody told that in high level languages one page per file (or was it per function) was ideal. I was writing mostly in assembly those days, and couldn't really understand.
The cognitive perception in our brains tends to break things down, no matter. We break down and abstract. We analyze and synthesize. We iterate until we understand.
For some years I have personally used a token-based folding editor called Winf. It's old now, proven by the fact that the single Windows exe file is 144 kB. With its folding, I decide what a fold is: any section of code. This way I structure it any way I like. And I change on the fly. Some times it's a function, or it may be a group of functions or a block of code. Hierarchical folds: folds within folds.
A closed fold is seen as started with three dots (above) and may contain nested folds. This way, a structured fold may contain 10000 safe lines, because I easily at any time would reckognize how to paint my brain with its semantics.
As long as I can open and close, enter and exit, and open all (to mimic a plain non-folding editor) I am content. I need all these functions. And I need to manipulate folds, delete, copy, copy-push and move-push to (and from) a stack. Also, indent and outdent. All this, because some bright guy saw my needs before me and invented the folding editor.
A fold has a crease, the top of it, where I must enter a one-line comment, since three dots are not of much help. The fold tokens live in the source file as standard comments. Therefore also this one-liner is visible in notepad.
However, with the particular Winf editor I miss the file and function views, which modern editors have (even some folding editors have this, I believe) And an integrated multi-file search. (I use grep in a separate window now, all too cumbersome.)
Some times I fold an unfolded file to easier work out what it is supposed to do. This often makes it easier to pinpoint any error. Of course, errors would also me made with folding - and some times not seen because of too much folding.
Still, personally I quite like working with files this way. File size becomes irrelevant, just like the sum of lines in a set of files seems rather an uninteresting measure - at least not before somebody wants an SLOC per hour figure.
Working with files this way constitutes a graphical tool. It does not stand behind traditional (not so new as some think) graphical tools. Letters are graphical better than most. And both figures and letters are covered by the common curriculum of semiotics. It is the abstraction level that counts, not figures or letters per se.
As said, file size is abstracted away. And the contents abstracts well into understanding. This token-based editing metaphor should, in my opinion, be included with major IDEs, like the syntax-dependent code folding editor Visual Studio. As an orthogonal extra or add-on tool it's wonderful.