EmbeddedSystems, Europe
www.es-mag.com
June 2000, pp.57-68
Cover story:
Taking the pain out of multitasking
Designing software for multitasking and multiprocessing systems is one of the most difficult things to get right, as many failures in the field testify. The author claims that the theory of communicating sequential processes (CSP) can streamline development and produce fewer errors. It has formed part of dedicated languages such as Ada and occam but can also be easily applied to more popular languages such as C and Java.
By Øyvind Teig
Appended: Error in (and comments to) magazine's printed issue
Programming for multitasking or multiprocessing remains one of the most difficult areas in software design. For most developers, concurrent programming means having to deal with objects that can guarantee mutual exclusion to prevent individual tasks from corrupting each other's data, and help in passing data from one task to the other.
The situation is complicated by the architecture of various real-time operating system (RTOS) products that employ broadly similar concepts but differ in the way that mutual exclusion and synchronisation primitives are used. Some RTOS implementations allow tasks to share memory with each other so that they can exchange data readily. Semaphores are vital in this scenario. By obtaining a semaphore, a task can generally ensure that only it has access to a particular block of shared memory to work on. When it releases the semaphore, the task gives permission for others to use that memory.
Unfortunately, it is a scheme that relies on trust. You have to remember to release a semaphore, and you have to acquire nested semaphores in the same order in all clients. Wrong usage may result in a frozen system that only the watchdog is able to rectify. This could happen after years of error-free operation, and you have no tool to analyse the situation at design/compile-time.
So, the concurrency primitives that traditional RTOS implementations deliver are quite often not secure and they operate at a low level, meaning that you have to very be good at it. Synchronisation and protection, semaphores, critical regions and monitors have to be carefully handled. An object-oriented (OO) methodology such as UML can help. However, some of the OO traits seem to clash with the way in which real-time programmers think. Dynamic linking and heap-based garbage-collection are some of the problems. SDL is also often used in design of real-time systems. The tools can be used to generate code automatically, which can speed up development. A potential problem with SDL is its use of
theasynchronous semantics. The semantics demand that all communication buffers have to be infinitely deep, in concept. This is nice for some deadlock problems but also must cause worries of how buffer overflow is handled.
In a way, the theory of Communicating Sequential Processes (CSP) is an non-exclusive alternative to these methodologies. UML promotes the idea of a system architecture in which multiple objects communicate with each other by sending and receiving messages. Many designs in SDL revolve around the use of message-sequence charts in which objects communicate by exchanging messages. At the system design level, the idea of objects communicating through well-defined channels is already an idea accepted by many developers.
In principle, it would be easier if implementation environments supported the same semantics as those used by modelling environments such as SDL or UML.
At the implementation level, concurrent programming does not necessarily mean having to deal directly with mutual exclusion (mutex) primitives to restrict access to shared objects. Contrary to the Unix-style environments you can forget about semaphores.
A task, as usually envisaged by concurrent programmers, is considered as the traditional multithreading entity. It is supported by a rather visible run-time system, using critical regions or semaphores for protection and synchronisation. A task-based environment gives the programmer a high degree of control, it is tuneable. However, tasks are typically coarse-grained because switching between them is considered an expensive process in terms of performance. For the purposes of this article, a task may run in an unprotected or a protected memory environment. In the latter case, a task is considered to be equivalent to what Unix developers call a "process".
are often considered to have finer granularity than tasks although, in the context of RTOS implementations, threads and tasks are often considered synonymous. In Java, threads have built-in support for concurrency making inter-thread communications simpler for the programmer to write. Java uses the synchronized keyword and methods such as wait, notify and notifyAll to coordinate the activities of different threads. In practice, Java threading is difficult to use.Threads
Although Java has built-in support for concurrency, the situation is not much better than when using semaphores. You may easily forget the synchronized keyword, or use of methods wait or notify, with the result likely to be deadlock. With nested waits it gets no easier. This means that you have to use the mutex primitives in a way that is in fact defined by how other threads use them. You cannot look in "this" thread only and forget about the others. This has been called lack of WYSIWYG semantics.
A third form of concurrent programming is defined in Professor C.A.R (Tony) Hoare’s Communicating Sequential Processes (CSP) theory [1]. Unlike Unix processes, which can share memory and have direct access to semaphores and other mutex primitives, CSP entities can only dynamically communicate through channels. They do not share memory and are designed so that explicit semaphores do not have to be used to synchronise them.
One big advantage of using CSP is that systems built using them can be analysed – tools exist that can demonstrate that the concurrency in a system is correct and that traits such as deadlocks or livelocks will not occur. Although not in the mainstream for many developers, the concept has been used in the field for many years and CSP theory continues to develop. The latest book dates from this year [2]. In principle, CSP supports fine-grained concurrency. You may have thousands of processes in a system if you use an efficient implementation of CSP.
The ability to analyse CSP-based systems stems from its algebraic properties (it is a process algebra). CSP may be considered as a "pattern" for concurrent programming and can be used in the specification, design and implementation phases.
The threshold to start using CSP may seem high and CSP it’s a topic that does not appear often outside academic literature, even if many developers would feel at home when they see it. CSP may have been noticed as the basis of the Ada rendezvous model or through the occam programming language [3] developed by Inmos (now part of ST Microelectronics) for the transputer. However, CSP does not demand a dedicated language, it is possible to provide C, C++ and even Java with a CSP API.
The JCSP Java CSP [6] API developed at University of Kent at Canterbury, UK, is a library of packages providing an extended set of CSP primitives for Java. One package includes process wrappers that provide a channel interface to Java's AWT library, which is used to build graphical user interfaces. Instead of the Java AWT event model, buttons and dialogue boxes are active CSProcesses. For example, a button CSProcess will send button-press messages over channels to other CSProcesses, and there is one CSProcess per button. There is presently no CSP API based on Microsoft Foundation Classes (MFC) for Windows environments.
CSP seems to have a natural fit with object-oriented methods. It supports hierarchical decomposition and, because processes communicate only through defined channels, supports encapsulation. CSP at least fits the ideals of object-oriented development. If processes were to become as cheap as objects, CSP could become a serious supplement to object-oriented or other techniques.
If you need to verify that an algorithm that controls lights at a road junction is free of race hazards, you can model it with a CSP tool. Then you can later convert the model to a program one-to-one, right down to using one process for each bulb. The implementation would itself be a runnable model, narrowing the problematic "semantic gap" between design and implementation.
In one application, we at Autronica used the now obsolete transputer and the occam language, which has been ported to a number of processor architectures. For communications with off-board I/O chips, we used the I2C bus.
The system was designed by having one process to handle I2C, and channels to/from a process to handle the I2C control lines. This process was also used by other clients that needed to exercise some of the other local I/O pins. We had at least one communication over those internal channels per I2C bus-line edge, and we could still run at almost full I2C speed. We used commands along the lines of "set SCL line high" and so on.
With a process switching time of 1ms this architecture was viable.
To explain how CSP expresses concurrency, consider a simple system in which one process needs to obtain a block of data from a disk-drive controller. To prevent other processes from grabbing parts of the data before the reader process has finished, the controller can be locked to allow exclusive access to the reader once access has been granted, until it has been released.
This type of system would be described in this way:
DISKCONTROLLER = (obtain->release->DISKCONTROLLER).
READER = (obtain->read->release->READER).
There are two defined processes, DISKCONTROLLER and READER. The sequence defined in parentheses refers to the states and actions of the processes. The obtain action is the same for both processes (as it is for the release action). The read action is performed only by READER, but it is an action that cannot be performed except after obtain. After that, the release action must take place before READER can do anything else. It cannot attempt to re-obtain DISKCONTROLLER until release has been performed.
You can think of a CSP process as a state machine. A group of state machines communicate by having common actions. Through these state machines, possible actions and the sequences they follow are declared at design time, making it possible for tools to analyse whether the system will suffer from deadlock.
The processes are connected using by creating a composite super-process, using this syntax: DEFAULT = READER || DISKCONTROLLER. You can think of READER and DISKCONTROLLER as concurrent processes that communicate using the acquire and release "channels". DEFAULT does not itself take part in the actions, it merely connects the state machines.
Input actions usually form part of a choice construction. CSP has a choice operator. If you are familiar with the POSIX select system call, think of the choice operator as select call worked into a theoretical framework. In the example above, there may be many readers but only one disk controller, in which case a list of possible reader processes are served by the resource. If presented with several obtain actions, the disk controller may have logic that lets it serve one reader ahead of others. The other readers would block until the disk controller got around to serving them, once another reader initiated the release action.
One could argue that channels are rather "stiff". Observe that processes may have names but communication is done over named channels, not with explicitly named processes. Each process does not need to know the name of any other, just the channels (that it uses). The super-process handles the connection. Channel naming is different to the original version of CSP, a change made by Hoare between the original description in 1978 and the 1985 version. In the meantime, he had participated in the development of the occam language together with David May at Inmos.
An advantage of this approach is that, should one of the processes terminate, the super-level could connect the "free" end of the channel to another process instead, without the sender having any idea of what's going on. No data will be lost in the process.
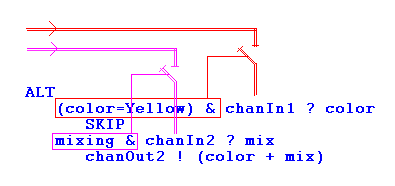
Figure 1 (above): ALT switches
The figure shows some occam syntax and how it works. There are two channels connected in the ALT choice construct consisting of two input guards. Guards determine whether data is ready on a channel and act as virtual switches. A sender will block until the channel's "switch" is closed and a message can be handled. This mechanism is available in all CSP systems.
The ALT statement usually sits on top of a while loop. Whenever an action has been served the ALTs structure is rebuilt to see if anything has arrived. This is not the same as the retest that you have to perform with Java's monitor. A Java thread may be woken up even if somebody else had grabbed the resource before it, and it will have to continue waiting.
In the example the process will always block on the channels (having both switches open is illegal). There are two other types of ALTs: one that lets you implement polling of the channels and one that can time out. If no new data arrives, the process would be able to do some more processing before it eventually arrives at the ALT again. This helps prevent the decomposition of larger systems into thousands of tiny processes. However, the overhead of an ALT is o(n) per message, reflecting that it is one of the most complex and expensive constructs of occam.
Inferring from the above, the only way to dynamically communicate between processes is over channels. Statically, processes may be started with initial values, and they may return final values, but only to the father process. We could say, then, that CSP is algebraically analysable message passing.
Although CSP is based on synchronous channels, you can use it to model asynchronous communication as well as mutex mechanisms like semaphores and monitors. Connecting to an asynchronous world or designing producers that need to be ahead of consumers is also possible with synchronous elements. It's being done all the time. Some of the techniques that could be used are connecting to interrupts, polling I/O controllers and inserting buffer processes. Losing data is a design issue, it won't be by accident.
Because channels are such an inherent part of CSP, you need to describe what data will pass through them. This defines a process' interface. Look at Listing 1 to see how protocols may be represented in C and occam. A protocol in this context has tags (like built-in enum commands) and handles dynamic data (like variable-sized arrays) - all bundled in a struct-like definition.
As we can see from the listing, in a C struct, all arrays have to be defined with a compile-time known array size. If the producer and consumer agree on the protocol above, the struct is fine if you can accept to always send sizeof theStruct number of bytes. If not, you're in trouble. The trick may be to write Perl scripts to analyse the struct and have it generate sending and receiving side C stubs. Observe that an occam equivalent of len1 does not exist because the array size is constant.
The occam example of the same is handled directly by the language, and compile-time or run-time verification is done to avoid overflow of the receiving side's arrays. The compiler verifies that the same protocol is used at both channel ends. Returning to CSP talk, the semicolons in the occam protocol definition defines process synchronisation points. So sending and receiving of verOfProduct would not be finished before the parties involve in commandList. With quasi-concurrency on a single CPU this could be slow if you did not have a very fast context switching time.
Your requirement of what "real" time is defines how you would implement the application. The granularity of processes and how the protocols are defined are important. How the run-time system is implemented is also crucial (presently you would find process switching times in the 100ns to 100ms range), together with the platform you would be running the code on.
A protocol could be made even more dynamic than occam's - the protocol definition in the Java CSP APIs is able to send any Object (and therefore also a new protocol description and protocol driver) over its channels.
One potential source of deadlock in a CSP system is if a task fails to reply to a process expecting one and there is no timeout set on the channel. We use a naming scheme to help with this. Simple message sequence diagrams are hidden in the name scheme: FooReNack is followed by NackEnd (Nack reply) or FooEnd (proper Reply).
In typical implementations, you will probably put the state machine(s) inside a process, thread or task. On some of our boards we communicate over a dual-port memory. We have two channels in each direction in the dual-port. The channels are given synchronous semantics (i.e. we never time out or overflow). However, a failure at the physical level, such as a dead processor at the other end, is detected by a separate process. This times out on missing hardware semaphores catches [11]. It is natural to break the functionality down into several processes, each with its own state machine.
In our case we used occam as our programming language, and then automatically generated quite readable C code using the SPoC occam to C compiler [12]. Aspects of our project have been described [13]. One interesting thing to note is that in order to handle the channels and scheduling, another level of state machines is generated by the translator: each process is packed into a large switch/case statement, which again may be nested. These machines have not been exclusively written in the occam program, they are in generated C to solve the semantics required.
An implementation of an embedded system does not necessarily require pre-emptive scheduling. Co-operative scheduling, handled by a run-time scheduler will often do. Typical descheduling points would be at all blocking points such as communication and timeouts. Such a system would be designed with processes in abundance, and they would be considered cheap, both when it comes to process switching times and stack need.
Some occam implementations compilers calculate exact maximum stack need - recursion is not allowed. It would not be natural to map a process straight down to a native RTOS thread - if the system were running on top of one. We can see this tendency with the two real-time Java's that have been defined. Both J Consortium's "Real-time core specification for the Java platform" [4] and Sun's JSR-000001 "Real-time Extension Specification" [5] specify JVMs and run-time systems which are more lightweight than standard, which have default thread memory pools in the megabyte range.
Relying on co-operative scheduling requires special attention to loops that do not contain natural descheduling points. At the end of the day this concern defines whether co-operative scheduling is acceptable. The two Java CSP APIs are built on Java's required pre-emptive scheduling. However, in my experience, real-time systems require much less pre-emptive scheduling than I originally thought, as long as hard real-time requirements may be met by the built-in pre-emptive interrupt system or some other hard scheduling technique.
Designers of priority-based systems worry about priority inversion, in which a high-priority task may be forced to wait on a lower-priority task that owns a resource it needs. These days the priority-inheritance protocol and priority-ceiling protocols (PCP) are popular ways to solve handle the priority inversion problem. The whole idea is to dynamically raise the priority of a thread to "my" level (if I wait for this lower priority resource while another less prioritised user than me has it) or to the maximum level of all possible users of the resource. However, some kind of scheduling granularity must be agreed upon. In a football match, the other team's players can take the ball at any time. But in order to score, the ball "resource" must be held for a while. Could priority inversion problem solutions be simpler if we did not use pre-emptive scheduling?
For priority inheritance to work with CSP, the run-time system would have to know who is communicating with whom. Only the connecting CSP layer would know which processes could communicate. At run-time this is known by the run-time system only when the second channel participant arrives. I am not aware of any CSP run time system that does PCP, maybe because it is not much needed.
Instead, design correctly. A simple set of design patterns may be used. Create a service process at your priority that can help with lower priority communication. With this concept, no priority needs to be increased, this is fine because the background low-priority server is held in the background and not all of a sudden competing for CPU cycles with "me". Alternatively, insert buffer processes. Those design-rules also help with deadlock avoidance. Or design the low-priority server as handling its clients "fair", don't let any client re-own the server all the time. Whether this is acceptable depends on the scheduling granularity: is the resource an FFT software implementation that could be pre-empted, or a process controlling an FFT chip that has to run to completion? The general design rule would be to shun priority as much as possible, in my experience more than 3 levels should be avoided, excluding interrupts.
When it comes to implementation languages, occam is a runnable language based on CSP. You could try to use CSP methodology by f.ex. building with POSIX calls, even if such a system would fast become just message passing. The synchronous selected choice with guards in CSP is more than just the select call.
For clean C you could use the CCSP library developed at University of Kent at Canterbury, UK [14][11]. We are developing a port of CCSP to run on top of VxWorks, on a 386EX embedded machine. This will shortly be available for free downloads - in the bazaar spirit the port has been financed by the company I work for. The CCSP port runs all non-blocking I/O processes in the same VxWorks task. See C and CSP sidebar.
CCSP and SPoC display two interesting traits. Both use co-operative scheduling. SPoC takes its input from the occam sources, and knows what a process is. It is therefore able to "flatten out" the process hierarchy and place every process just one call above the scheduler. No matter which process we are in, the scheduler is only one return away from the process body. All local process variables that need to survive through descheduling points are placed in a single large tree that is allocated all the way up at "main". It therefore uses only one stack, making stack overflow check very cheap. With CCSP the sources are in C, flattening out the process hiererachy and doing tree variable placement by hand would be too much. It therefore has to maintain one stack per process.
The CCSP library started its life as the kernel for the KRoC occam compiler for Linux [15] [12]. In the newest release KRoC is able to have TCP/IP sockets connected to channel edges.
If you want to try out CSP APIs for Java, you should check out JCSP mentioned earlier [6] or CTJ developed at University of Twente, The Netherlands [16][13]. JCSP runs on top of a standard JVM. See Java and CSP sidebar.
The Magee & Kramer Concurrency book [7] shows how Finite State Processes (FSP) (FSP is derived from CSP and other process algebras) are used to model problems. The models are then later programmed in proven correct Java.
The FDR2 tool from Formal Systems is the industry standard CSP tool [17][14]. It is priced in the same way as some high-end CASE tools, so I have not been able to do any "hands on" this tool.
Both SPoC and KRoC and of course CCSP will work with native C.
Lastly, don't forget Ada, it is quite alive and well, and its concurrency model is also based on CSP.
I feel that OO and CSP are not mutually exclusive. In concurrent systems UML could be useful. Even class diagrams on their own would make sense if an OO language were used for implementation. But I feel that CSP probably maps better to Structured Analysis, Structured Design (SASD) than to UML. We are watching the development of the real-time UML standard. The planned run-to-completion semantics there have a lot of CSP in them. Personally I like SA/SD process/data-flow diagrams and UML sequence diagrams.
Using the CSP methodology has worked well for us, we have done this on several projects over the previous 10 years. With "secure" and cheap processes, the implementation is a reckognisable imprint of the design. It pays, we have seen it reduce service trips all around the world. Concurrent programming doesn't have to remain one of the most difficult areas in software design.
C and CSPstatic void DualPortAcquireAndRelease (Process *p,
Channel *chanAccessIn[],
Channel *chanAccessOut[],
... Other Channels
Time timeToTimeOut)
{
... Locals
while (running)
{
iOfChanIn = ProcAltList (chanAccessIn);
ChanIn (chanAccessIn[iOfChanIn],
&protPdpAccess, sizeof(ChanPdpAccess));
switch (protPdpAccess.prot.cmd)
{
... Handle input from one of the channels
}
}
}
Listing 2 (above): CCSP exampleListing 2 shows a fragment of CCSP clipped from an application we work on at the moment [18]. CCSP types are Process, Channel and Time. DualPortAcquireAndRelease is a proper Process that has been initialised by the father Process. The first parameter is a pointer to "this" Process. The channels pointed to by the arrays have also been initialised and connected by the super level. The ProcAltList blocks the receiver until something arrives on a channel. When data has arrived, the iOfChanIn index is returned, and data in the channel is taken. The call to ChanIn then unblocks the sender. The program inside while(running) will run non-descheduled until timer or channel I/O needs to to be handled. |
Java and CSPimport java.util.*;
import java.io.*;
import jcsp.awt.*;
import jcsp.lang.*;
class MyConsumer implements CSProcess{
private final ChannelInput in;
public MyConsumer (ChannelInput in_){
in = in_;
}
public void run(){
boolean running = true;
while (running){
Protocol prot = (Protocol) in.read();
Label label = (Label) prot.read_Label();
if (label == Label.Integer_NoAck){
int now = ((Integer) prot.take_Element()).intValue();}
else if (label == Label.String_Integer_NoAck){
String text = (String) prot.take_Element();
String number = ((Integer) prot.take_Element()).toString();
System.out.println (text + number);}
else if (label == Label.OutputStreamWriter_NoAck){
OutputStreamWriter outputStreamWriter =
(OutputStreamWriter) prot.take_Element();
try{
outputStreamWriter.write ("Hello!");
outputStreamWriter.flush();
System.out.println ("Wrote 'Hello' to disk");
}
catch (IOException e){
System.out.println ("Could not write to disk (IOException)");}}
else if (label == Label.Exception_NoAck){
Exception e = (Exception) prot.take_Element();
System.out.println (e.toString());}
else if (label == Label.Flush_NoAck){
System.out.println ("Label.Flush_NoAck");
running = false;}
else{
System.out.println ("Label not known, stopping..");
running = false;
}
}
}
}
Listing 3 (above): JCSP exampleListing 3 shows a producer blocking for input on the "in" channel. Whenever data has arrived, the Protocol contains either an Integer, a String and then an Integer, an OutputStreamWriter, an Exception or an administrative command. The Protocol class has been built on an example given with the JCSP release, the difference being that the command itself is also a proper Object. Now you may forget about synchronized, wait, notify and notifyAll! |
- [1]
- C.A.R. Hoare, "Communicating Sequential Processes". Prentice Hall, 1985.
- [2]
- Steve Schneider, "Concurrent and Real-time Systems, The CSP Approach". www.cs.rhbnc.ac.uk/books/concurrency/
- [3]
- "occam2 Reference Manual". INMOS Ltd, Prentice Hall, 1988 (C.A.R. Hoare is series editor) ISBN 0-13-629312-3. archive.comlab.ox.ac.uk/occam.html
- [4]
- J Consortium: www.j-consortium.org
- [5]
- JSR-000001: java.sun.com/aboutJava/communityprocess/jsr/jsr_001_real_time.html
- [6]
- JCSP - www.cs.ukc.ac.uk/projects/ofa/jcsp. Examples from this library is also given in Doug Lea's "Concurrent Programming in Java" 2.ed.
- [7]
- Magee & Kramer, "Concurrency - State Models & Java Programs". www-dse.doc.ic.ac.uk/concurrency/
- [8]
- Per Brinch Hansen, "Operating System Principles", section 7.2, Class concept for monitor. Jyly 1973. Later used in concurrent Pascal.
- [9]
- C.A.R. Hoare, "Monitors: an operating system structuring concept" Communications of the ACM 17, 1974
- [10]
- Per Brinch Hansen, "Java's Insecure Parallelism", ACM SIGPLAN Notices 34,4 (April 1999), 38-45
- [11]
- Øyvind Teig, "Ping-Pong scheme uses semaphores to pass dual-port memory privileges", EDN, 6th June 1996. Also see http://www.autronica.no/pub/tech/rd/pub_details.html#PingPong
- [12]
- SPoC occam->C compiler: http://www.hpcc.ecs.soton.ac.uk/software/spoc
- [13]
- Øyvind Teig, "Non-preemptive occam in DSP real-time system", Real-Time Magazine, 3Q98. Also see http://www.autronica.no/pub/tech/rd/RealTimeMag_3_1998/Real-Time_Magazine.htm
- [14]
- J. Moores, "CCSP - A Portable CSP-Based Run-Time System supporting C and occam". WoTUG-22. Architectures, Languages and Techniques for concurrent systems, p.19-36. Edited by B.M.Cook. ISBN 90 5199 480 X, 4 274 90285 4 C3000, ISSN 1383-7575. www.quickstone.com/ccsp/
- [15]
- KRoC occam for Linux: www.cs.ukc.ac.uk/projects/ofa/kroc/
- [16]
- Gerald Hilderink et.al, "A new Java Thread model for concurrent programming of real-time systems", Real-Time Magazine 98-1, pp.30-35. www.rt.el.utwente.nl/javapp/
- [17]
- FDR (Failures-Divergence Refinement), an CSP tool from from Formal Systems (Europe) Limited, www.formal.demon.co.uk/FDR2.html
- [18]
- CCSP example written by Åge Stien at Navia Maritime AS, Div. Autronica.
|
Øyvind Teig is Senior Development engineer at Navia Maritime AS, division Autronica. He has worked with embedded systems more than 20 years, and is especially interested in real-time language issues. Several articles by the author are available at www.autronica.no/pub/tech/rd. |
Error in (and comments to) magazine's printed issue
This chapter is dated 12-03-2004.
Error
- The not was missing. (In magazine: page 58, center column, top)
- The important thing to remember is that with CSP you need no explicit mutex or semaphore. I wish I was able to express this better (redemption: see below). You can write a model of a semaphore implementation in CSP, to make sure you have got it right. But the occam language (which is a runnable subset of CSP) has no semaphore:
- All protection is done by explicit processes, all dynamic communication over channels.
- Protect an array, object or I/O chip or another process:
- Pack all processing of it inside a process and make "access routines".
- Occam has usage verification and/or checks, it helps you get it right as well.
- The KRoC compiler [15] does have four new synchronization primitives: BUCKET, RESOURCE, SEMAPHORE and EVENT and - the last two are discussed in [19], which states that:
... The new primitives are designed to support higher-level mechanisms of SHARING between parallel processes and give us greater powers of expression.
... They demonstrate that occam is neutral in any debate between the merits of message-passing versus shared-memory parallelism, enabling applications to take advantage of whichever paradigm (or mixture of paradigms) is the most appropriate.
... The intention is to bind those primitives found to be useful into higher level versions of occam. Some of the primitives (e.g. SEMAPHORE) may never themselves be made visible in the language, but may be used to implement bindings of higher-level paradigms (such as SHARED channels and the BLACKBOARDs). The compiler will perform the relevant usage checking on all new language bindings, closing the security loopholes opened by raw use of the primitives.Comments
- Figure 1 did not turn out very illustrative in the article, since in occam, indenting is compulsory to 2 spaces per level. Also, during alignment with magazine's layout style, the boxes did not align with ALT guards' conditions.
(In magazine: page 58)- Guards determine whether data is ready on a channel and act as virtual switches.
ALT's are so simple yet so difficult to get right in a description!
- Whenever the program arrives at an ALT, the ALT structure is "built" by the runtime system.
- If or when anything has arrived on any of the channels: if data has arrived, if timeout has occured or if you just want to poll, the ALT is "torn down" and the appropriate process code will run.
- When processing has been finished, the ALT is reentered.
- There is no active polling in this!
- The switches I talk about are the conditions in each ALT component, and they act as physical switches would. If in occam, a boolean condition is not explicitly written (like just "chanin2 ? mix"), it reads TRUE meaning that if there was a switch there it would always be closed - or it would be just a wire (channel without switch).
- (In magazine: page 58, center column, bottom)
- About the state machines that SPoC generates I say "which again may be nested" in the article. This is not accurate. The article later describes that the process hierarchy is flattened, which is a way to actually make the original nested structure of occam as a set of one-level state machines. To see examples of these state machines, see http://www.autronica.no/pub/tech/rd/RealTimeMag_3_1998/Real-Time_Magazine.htm
(In magazine: page 64, left column, middle)- About popular Priority Inheritance (PI) protocols: see
Victor Yodaiken, "The dangers of priority inheritance" at http://www.cs.nmt.edu/~yodaiken/articles/priority.ps.- We have not "developed" the port ourselves (just financed it). The porting proper has been done by the author of CCSP. Se [14]
- Now you may forget about synchronized, wait, notify and notifyAll!
With the JCSP and CTJ APIs, it has nothing particular to do with Listing 3!- [8], [9], [10] are references needed in an earlier draft of the article. See http://www.autronica.no/pub/tech/rd/pub_details.html#TrygtMedJava
More references
- [19]
- Peter H. Welch and David Wood, "Higher Levels of Process Synchronization". In "Parallel Programming and Java", A. Bakkers (Ed), IOS Press, 1997, ISBN 90 5199 336 6. (Proceedings from WoTUG-20, http://wotug.ukc.ac.uk/parallel/groups/wotug/index.html)